
This post is the output of this book.
Advanced Algorithms and Data StructuresIf you want to check all the code, go to my repository.
What is cache?
Cache is a kind of storage where we can read a target data in a short time. If it takes time to calculate/query the target data that is frequently used, it leads the performance problems in the application. If we have the data in the cache, we can quickly read and use it without waiting time.
It’s important to know that the cache size is not infinite. Therefore, we have to decide which data should be deleted from the cache that is already full when new data needs to be added. I think the following two ways are well known.
- LRU (Least Recently Used) cache: Delete the data whose referenced time is the oldest
- LFU (Least Frequently Used) cache: Delete the data whose referenced count is the lowest
I will explain how to implement LRU cache in this article.
What is necessary to implement for LRU?
What we need is basically only two functions. Set and Get.
- Set
- Add a new key-value
- Update the existing key-value and the timestamp
- Delete a key-value pair that is the oldest
- Get
- Search for the value corresponding the key
The best way is to be able to do the processes in O(1) time which means constant time. It’s important to do set/get in a short time.
How to implement LRU
Let’s consider the implementation details.
Using Hash Table
We need to have key-value. Then, using Hash table, dictionary-like data type is the first choice. It’s Map in TypeScript/JavaScript. We need to have the timestamp in order to know the oldest one.

Since it’s a hash table, reading and adding/updating a key-value pair is O(1). However, we need to know the oldest data. In this case, we have to traverse the array to know it. It’s O(n).
Using Linked-List
How can we know the oldest data in O(1) time? Using array is not a good idea even if it’s sorted because it takes O(n) to sort the array.
How about a linked list? The Head has the latest and the tail has the oldest data. If we know the Tail, it takes O(1) time to find the oldest data.
It’s necessary to sort the order to update the timestamp. What we have to do is to disconnect the current connecting arrow followed by connecting the arrow to another node. It takes constant time even if there are a million elements.

However, reading data takes O(n) because we have to find the target key by traversing the list. Therefore, it takes O(n) for read/add/update.
Conbination of Hash Table and Linked-List
Let’s consider this further. How about using both of them to overcome the slow process? Look at the following table to know the speed.
| Hash Table | Linked-List | Hash Table + Linked-List | |
|---|---|---|---|
| Find key | O(1) | O(n) | O(1) |
| Delete | O(n) | O(1) | O(1) |
| Add/Update | O(1) | O(n) | O(1) |
We can achieve O(1) for all operations by using both. Firstly, Map has key-value pairs. The key access is O(1). We store a linked node as a value. Since this node is one of the elements in the linked list, we can update the timestamp in O(1).
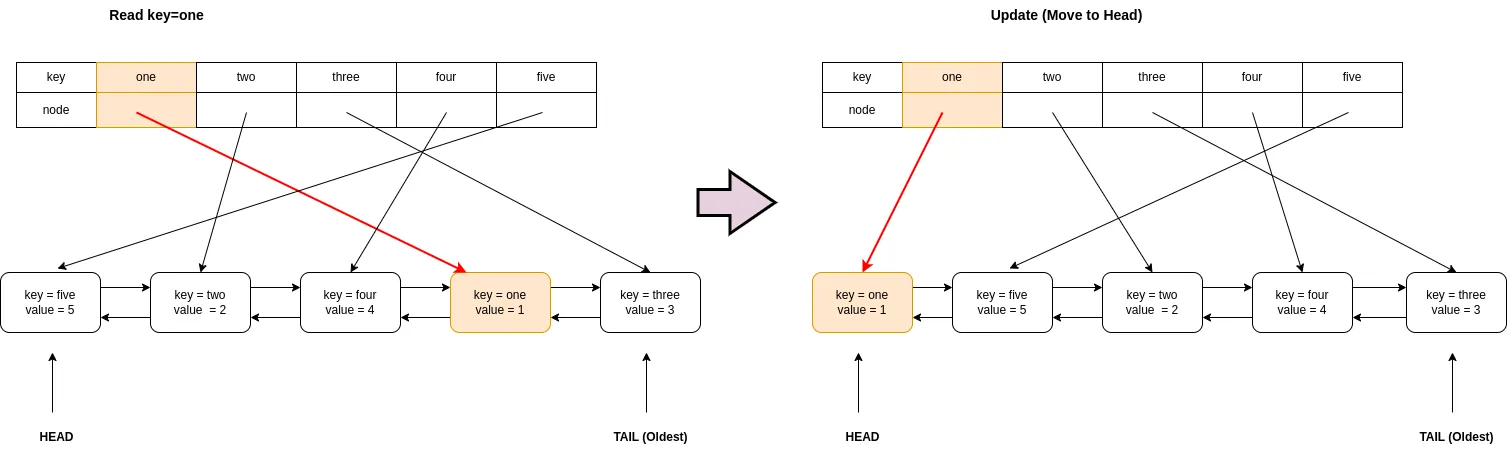
If we use double-linked nodes, it’s enough to have only Head and Tail nodes.
Double Linked Node
Let’s implement double double-linked node first. We need key-value and two pointers. One is to the previous node, another is to the next node.
export class DoubleLinkedNode<T> {
constructor(
public key: string,
public value: T,
public previous: DoubleLinkedNode<T> | undefined = undefined,
public next: DoubleLinkedNode<T> | undefined = undefined,
) { }
}LRU Cache
Constructor
As mentioned above, it’s enough to have a head and tail. We don’t need to have a so-called LinkedList here. mapping is a Hash Table. The value is a linked node. Last but not least, we have to determine the cache size because memory is not infinite. If the current size reaches the max size, we have to delete the oldest entry.
import { DoubleLinkedNode } from "./DoubleLinkedNode";
export class LRUCache<T> {
private head: DoubleLinkedNode<T> | undefined;
private tail: DoubleLinkedNode<T> | undefined;
private mapping = new Map<string, DoubleLinkedNode<T>>();
constructor(
private readonly maxSize: number,
) { }
}Get, Find the target value
It’s very simple. Try to get the data by the key name from the hash table.
public get(key: string): T | undefined {
const found = this.mapping.get(key);
if (!found) {
return undefined
}
this.moveToFront(found)
return found.value
}If the key doesn’t exist in the hash table, it must be added in the caller side. The implementation for moveToFront will be shown later.
Set data, add/update
We have 3 cases.
First, when the key exists the target node must be moved to the head.
Second, the key doesn’t exist and the current size reaches to the max size. We have to delete the oldest entry followed by adding the new data in this case.
At last, the key doesn’t exist and the cache has enough capacity to store data.
Let’s see the implementation.
public set(key: string, value: T): void {
const node = this.mapping.get(key);
if (node) {
node.value = value;
this.moveToFront(node);
return;
}
if (this.maxSize <= this.mapping.size) {
this.removeOldCache();
}
const newNode = new DoubleLinkedNode<T>(key, value);
this.addFront(newNode);
this.mapping.set(key, newNode);
if (!this.tail) {
this.tail = newNode;
}
}It’s easy to follow, isn’t it? When a new node is added, it must always be located at the head. The last if clause is for the first insertion. A single node is head and tail at the same time when there is only one node.
addFront
To add a new node to the head, the next pointer of the head must be set to the new node. If the head has already a node, the previous pointer of the node must be set because it’s now the second node.
private addFront(node: DoubleLinkedNode<T>) {
const oldHead = this.head;
if (oldHead) {
oldHead.previous = node;
}
node.next = oldHead;
this.head = node;
}moveToFront
The next pointer of the previous node must connect to the next pointer of the current node. It’s kind of a bypass.
Then, the target node must be the head. Therefore, previous pointer must be disconnected which means undefined must be set in TypeScript.
If it has the next node, the previous pointer of the next node must be connected to the previous pointer of the current node.
private moveToFront(node: DoubleLinkedNode<T>) {
const previous = node.previous;
if (previous) {
previous.next = node.next;
node.previous = undefined;
}
if (node.next) {
node.next.previous = previous
}
this.addFront(node);
}It sounds complicated. Scroll up to the explanation of Linked-List. The diagram helps your understanding.
removeOldCache
At last, we have to delete the oldest entry when the cache size reaches to max size.
The size check is not necessary if maxSize is checked that the value is bigger than 0 in the constructor.
private removeOldCache(): void {
if (this.mapping.size === 0) {
return;
}
const removedNode = this.tail;
if (!removedNode) {
throw new Error("tail doesn't exist.");
}
this.tail = removedNode.previous;
if (this.tail) {
this.tail.next = undefined;
}
this.mapping.delete(removedNode.key)
}Try to use LRUCache class
We implemented the LRU cache. So let’s try to use it. I added the following methods too in LRUCache `class so that we can check the internal state. It shows the head node first followed by the next node recursively.
public showCaches() {
console.log("--------------------------------")
if (!this.head) {
console.log("no chache has been registered.")
} else {
this.showNodeRecursively(this.head)
}
console.log();
}
private showNodeRecursively(node: DoubleLinkedNode<T>) {
const prev = `prev: ${this.keyValueOf(node.previous)}`;
const self = `self: ${this.keyValueOf(node)}`
console.log(`${prev.padEnd(20, " ")} ${self}`);
if (node.next) {
this.showNodeRecursively(node.next)
}
}This is the test code and the result.
import { LRUCache } from "./LruCache";
function run() {
const cache = new LRUCache<number>(5)
cache.set("one", 1)
cache.set("two", 2)
cache.set("three", 3)
cache.get("two")
cache.showCaches()
// --------------------------------
// prev: N/A self: (two, 2)
// prev: (two, 2) self: (three, 3)
// prev: (three, 3) self: (one, 1)
cache.set("one", 11)
cache.set("four", 4)
cache.set("five", 5)
cache.showCaches()
// --------------------------------
// prev: N/A self: (five, 5)
// prev: (five, 5) self: (four, 4)
// prev: (four, 4) self: (one, 11)
// prev: (one, 11) self: (two, 2)
// prev: (two, 2) self: (three, 3)
console.log(cache.get("three")) // 3
console.log(cache.get("two")) // 2
console.log(cache.get("unknown")) // undefined
cache.set("six", 6)
cache.showCaches()
// --------------------------------
// prev: N/A self: (six, 6)
// prev: (six, 6) self: (two, 2)
// prev: (two, 2) self: (three, 3)
// prev: (three, 3) self: (five, 5)
// prev: (five, 5) self: (four, 4)
}
run();The key “one” was removed when it reached to the max size. It looks working well.
Overview
Hash Table + Linked Node is a good choice to improve the cache performance because all processes can be done in O(1) time. It was easy to implement it. If we change the data structure to a priority tree. If you are interested in it, check the following post too.



Comments